Posts Tagged Data Engineering
Lessons learnt at Skyscanner: Part One
Posted by Michael Okarimia in Skyscanner on December 6, 2021
Working for six years as a Data Engineer at Skyscanner has taught me some valuable lessons on how to build software software that can run at the scale of an “Internet Economy” user base
Version 1.0 of the Cloud native Data Platform: A tangle of hundreds of parallel data pipelines
The first few years of my time at Skyscanner was focused on supporting part of the Data Platform which consumed data from the Unified Message stream (Kafka) and de-queued the messages into long term storage (AWS s3) and made this data available for querying in Hive Meta stores. This was done using containers running running a Java application which consumed the data and wrote it into AWS s3.
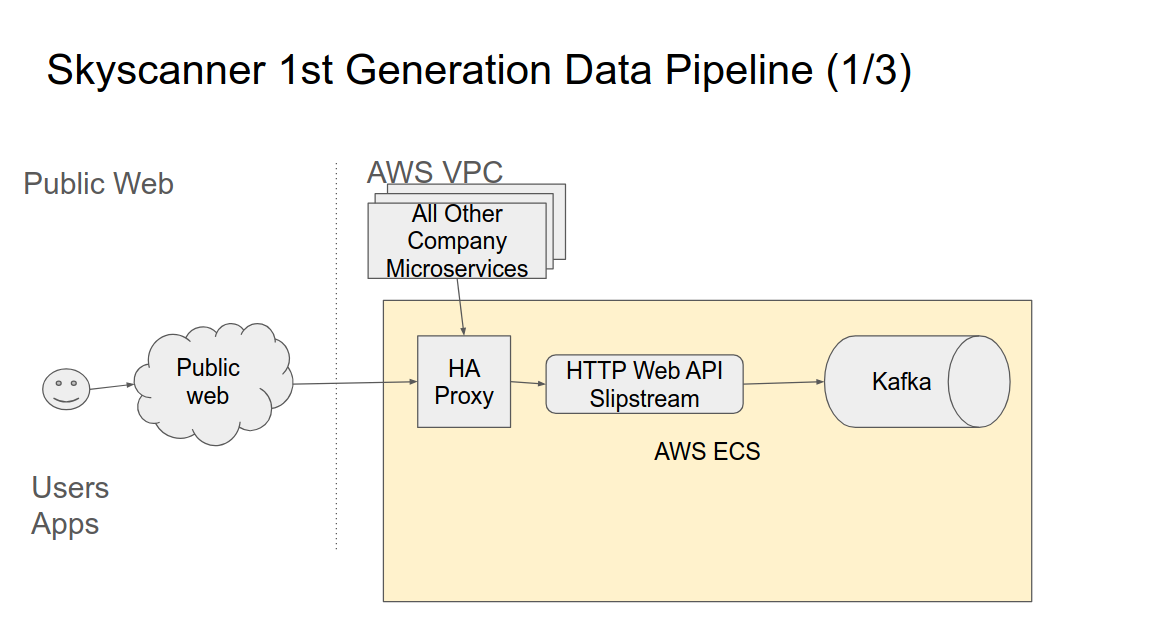
These containers ran software called Secor, and they were hosted instead AWS EC2 containers themselves running containerisation software called Rancher.
Data was partitioned in s3 by Kafka topic and then Date (dt=yyyy-mm-dd). Each new day would mean a new dt partition was created for existing topics by the Secor containers. The data was written in Parquet format. Volumes of data were in the order of around a Terra Byte a day.
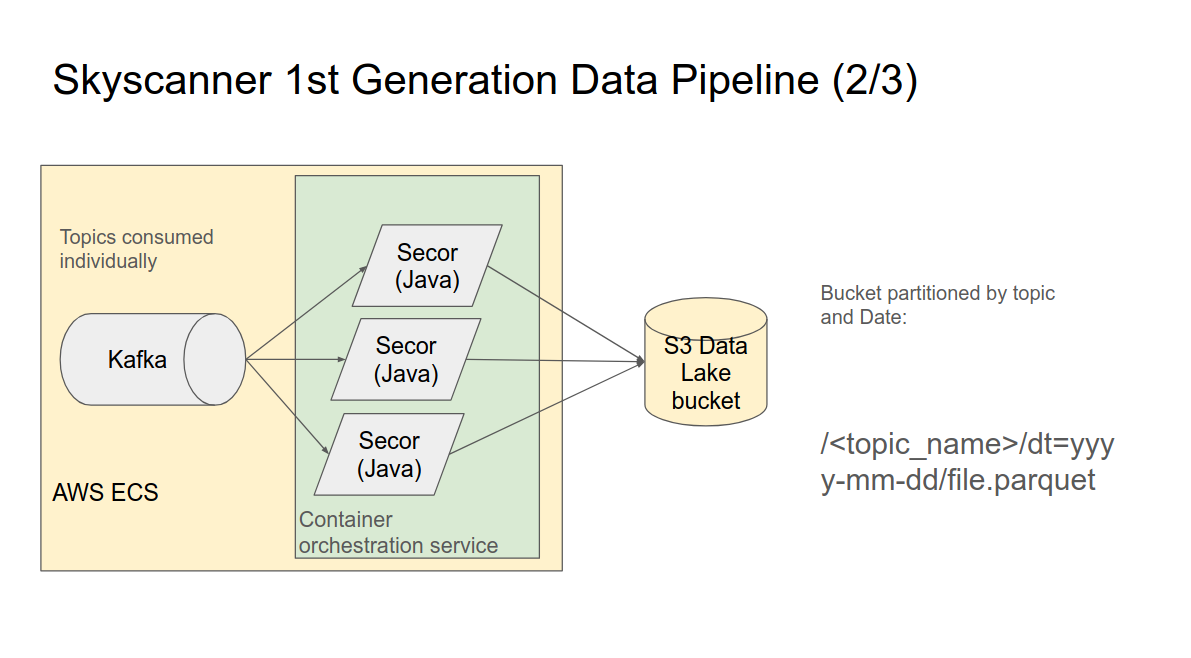
When new Kafka topics were created, Secor containers were instantiated with the corresponding consumer groups to read these topics and write them to AWS s3.
Once a day, the new s3 partitions by dt=yyyy-mm-dd would need to be added to Hive meta store in order for them to be queryable by downstream reporting tools such as Databricks.
I used Airflow to run DAGs which submitted a spark job for each topic once a day to a dedicated AWS EMR cluster. The spark jobs jobs would read the newest parquet files for that date, and generate the SQL DDL to create a new table in the Hive Meta store. A Python script in the DAG would read this SQL DDL and execute it against AWS Athena, which would drop and re-create the table and add the new s3 path to the table.

Operational Complexity
The were several hundred Kafka topics which were persisted into s3 and loaded into table in Hive meta-store.
There were at least two Containers consuming each Kafka topic, as each topic had at least two partitions. Each partition was consumed by one container. If there was higher number of messages produced to the topic, it would be scaled up to have more partitions, which would require an equal number of containers to consume that data. The largest topic had almost 100 partitions, and thus 100 containers to consume it.
The containerisation software ran on EC2 instances, which had to be manually scaled, which was error prone and time consuming. Many containers could run on a single EC2 host and often had to be manually scaled to different hosts.
Due to the hundreds of topics and tables involved in this system, it became complex and thus a rebuild of the Data Platform was commissioned. Me and my team were tasked to create a replacement.
This involves reaching out to customers of the platform to identify what the existing platform could not do and find places for improvement.
Problems encountered and addressing Customer’s Pain points
Customers biggest complaints regarding the data platform were, once you eventually onboarded a dataset, it was hard to find it, and difficult to check if it was complete.
- Onboarding a dataset was a multi step, complex series of manual tasks, which weren’t fully documented in one place.
- Schemas for new datasets had to be designed which required knowledge of the internals of the Data Platform.
- Testing new schemas required changes to production applications, and then more changes to promote that dataset to production.
- Even test Schemas required approval from group of data engineers who had limited time allocated for reviewing new schemas. As a result there was often a backlog of schemas for review, which created a bottleneck.
- Once the data was onboarded on to Production environment, discovery of the dataset was difficult
- There were no Data Quality metrics for a new dataset; no way to see if it was complete or on time.
Solving hard problems of scale and helping customers
In my next post I’ll describe how these problems were address by building a second generation unified Trusted Data Pipeline