7digital provide a web API platform for it’s customers to discover, stream & download music.  Every request to the public platform first is received by the Gateway API, which then redirects the requests to a dozen or so web applications of which have single responsibility, such as search or payments. These web applications read catalogue data from a database and return it to customers in XML format via HTTP responses.
7digital’s customers are spread around the world yet the API and its data is primarily located in London data centres. This means that latency, resilience and local targeting of content is not optimised for countries like India, where our largest music streaming service is located. In order to reduce latency for customers in Asia, we had the goal to migrate Catalogue Web applications and its corresponding database into an AWS region near the customers. By moving the APIs into the AWS cloud, it became possible to serve a greater volume of traffic by scaling up the number Web application running in parallel. For example, more search servers running in parallel allows for far more searches to be conducted at once.
Breaking down the problem
Cloud migration is such a large task, so we decided to break the work down into smaller units of deliverable features, each of which would provide value to the customer.
The part of the platform which our customers use the most, is the ~/track/details endpoint. It provides the access rights and other details of a given track.
The first part of the migration is to move into AWS this parts of the platform that power this endpoint.
The overall goal is to reduce response time for customers in around the world, particularly in Asia and the USA for all requests for this endpoint.
As a prerequisite it was also required to discover if the Gateway API, which governs access to the 7digital API services, is required to move into the same AWS cloud too.
What is the Gateway API?
All requests to the 7digital API are first received by the Gateway API, which governs access to specific features of the platform.
It’s duties include:
- Identifying the client making the request
- Checking to see if the client has not exceeded their daily request limit
- Ascertaining if the client is allowed to access the service they are requesting
If all the above conditions are met, it will then redirect the request to the appropriate internal Web application which will provide the requested service.
Although Amazon do provide a service similar to the Gateway API, it was soon discovered that their product would not be sufficient to provide an equivalent functionality, so a bespoke version was required.
The first deliverable feature from a customer perspective
The initial goal is to move ~/track/details endpoint with streaming data to AWS, ultimately for a client in India. This can be broken down into the following steps
- Deploy a version of the Gateway API, which can authenticate requests from the public web
- Deploy a portion of the 7digital API into AWS and have it operate in parallel with the existing 7digital API.
- Web applications that provide data regarding tracks in the music catalogue will be moved in the AWS Cloud
- Create a new database used solely for storing catalogue data. This database will be queried by the Web applications that need to fetch track details.
- Deploy the database into AWS with appropriate security and permissions so it can be accessed by 7digital’s web applications
- Populate the catalogue database with the data from London database.
- Keep the catalogue database in the AWS region up to date with new content being ingested in the London data centre.
To make this laundry list of requirements into a even smaller slice of functionality, we decided to use our CDN which sits in front of the Gateway API as part of the experiment to test the APIs in the cloud.
It was possible to redirect a specific url from one customer for one track so it is served from our cloud based infrastructure instead of London data centre based infrastructure.
Only a specific url would be redirected, the remainder of the current API Web traffic would continue to the London datacentre as normal.
This meant a request to the specific url would use the following parts of infrastructure which we successfully deployed into AWS.
The MVP
A stub Gateway API in AWS using nginx, which merely redirected to
A Metadata API
An Availability API
A Catalogue API
A MySQL database which can be accessed by aforementioned APIs
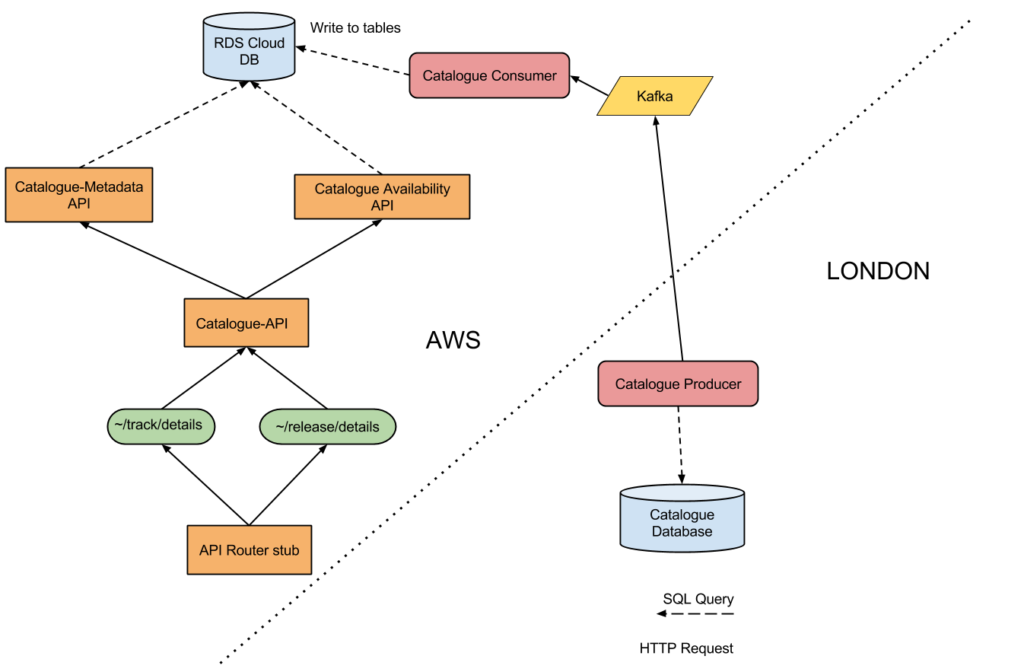
A service to listen for messages containing catalogue data and save it to a MySQL database (Catalogue Persister). This is a bespoke programme which listened for the 7digital formatted JSON messages and saved it into the 7digital specific database schema
A Kafka messaging system hosted on a server in the AWS cloud
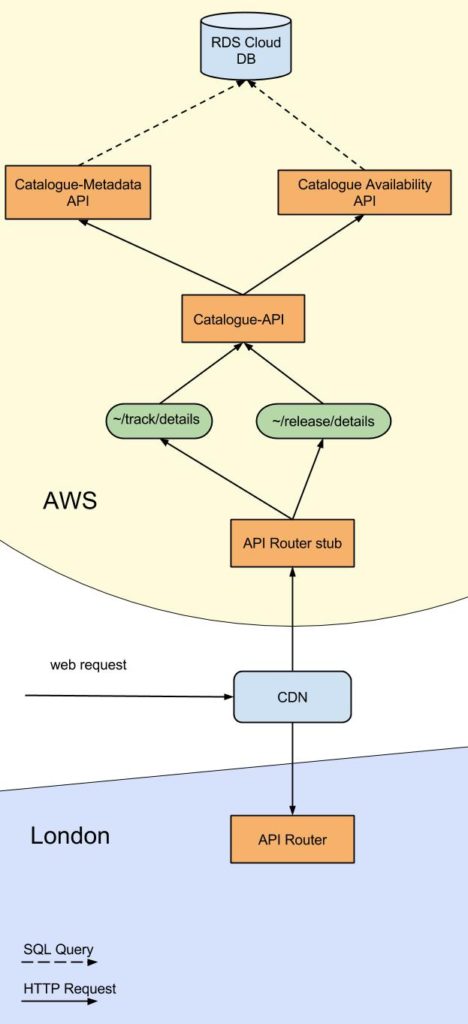
The stub Gateway API was achieved by using nginX software, which could perform most of the functionality the London Gateway API could. The client who is based in India whom we intend to use the AWS hosted version of the platform does not have a usage limit, so the stub of the Gateway API does not need to count requests.
Deploying the Metadata, Availability and Catalogue APIs to the AWS region proved that it was possible to have functioning APIs in the region. They called the MySQL database which we deployed to the same AWS cloud.
The Catalogue Persister service which listened to messages containing catalogue data worked as a proof of concept but was not production ready.
The idea of the persister was that we could send JSON formatted web requests to this service, and it could persist them into the MySQL database in the AWS cloud. However we soon realised that this would make it difficult to track what had been sent to the service and the feature was then abandoned. It did, however, fulfil its initial goal of populating data sent to it from London, but it was superseded by the Kafka messaging approach.
In the London datacentre there would need to be a service which read the data from the London database and send it the AWS region. We used Kafka service as the data integration point between London and the AWS region.
We opted to use a Kafka messaging system instead of the Catalogue Persister because it allows for every message to be logged and stored in chronological sequence; it became easy to replay all of the messages that had been sent. This is important in order to ensure the databases in London and the AWS region are consistent. The Kafka messaging service consisted of:
A server running Kafka software, inside the AWS VPC (Virtual Private Cloud)
A server running cluster management software called Zookeeper, which was to manage the servers running Kafka
A VPC configuration which allowed for the Zookeeper servers to receive requests from the public web and forward those onto the Kafka servers it was managing. The Kafka instances themselves are not accessible from the public web.
In our London Datacentre we created a programme which could read data from our existing shared database and send it to the Kafka service. We called this programme the Catalogue Producer. This was a bespoke programme which read data from our London database and pulled out the data for a single album. It then encoded it into a JSON format, and finally sent it to the Kafka messaging service in the AWS cloud.
This experiment worked as a proof of concept. To make this read for production we were going to change this programme so it could read the entire catalogue from the London database, convert it into many JSON formatted messages, and send those into the Kafka instance in the AWS cloud. Those messages could then be received and saved into the catalogue database in the AWS cloud.
It was proposed that we create a service in AWS which can read messages from Kafka an persist them into the AWS database, thus allowing data from the London database to be transmitted into the cloud database. However this was not started in 2015, and thus uncertainty #7 remained an open question.
Once the data was in the catalogue AWS cloud database, the portion of the 7digital API that was hosted in the AWS region could then display the data stored, thus fulfilling the project goals.
Summary of Outcomes
Catalogue API and supporting Metadata and Availability API’s deployed to an AWS region. A MySQL database was deployed there too, which the correct security access settings, so the three APIs could query that database. A stub of a Gateway API which could redirect external web requests to the internal Catalogue API was created. This allowed for the Catalogue API to be accessible via the public Web. We then made a change to 7digital’s CDN provider, Fastly, to allow a specific request to be redirected to the AWS version of the Catalogue API, instead of the London based API.
We also set up a Kafka instance in the AWS region, which was to act as a place where messages containing catalogue data were to be sent. This Kafka instance  only accepted traffic from the 7digital London office.
A service which could read a single track from the existing London database and push a message containing the track data to the Kafka instance was also created. This was called the Catalogue Producer. It’s goal was to send catalogue updates to the AWS database via the Kafka service.
Goal of moving the Gateway APIÂ was partially achieved when the scope of the functionality was reduced, but questions remain surrounding authentication and request limiting.
Although it was possible to serve live traffic, there remains questions of how effectively the platform would work. A/B testing would help use see what levels of traffic the new infrastructure could handle
The challenge of moving catalogue data from London to the AWS database was partially solved, whereby it was shown that is is possible to transmit a message containing the data to represent a album into a Kafka messaging service in an AWS cloud. This project served as an useful proof of concept and starting point for the migration of 7digital’s API into an AWS region.