Archive for category Automation
Solving problems of scale using Kafka
Posted by Michael Okarimia in 7digital, API, Automation, Cloud, DevOps on March 1, 2016
At 7digital I was in a team which was tasked with solving a problem created by taking on a large client capable of pushing the 7digital API to its limits.  The client had many users and expected their numbers to exponentially increase. Whilst 7digital’s streaming infrastructure could scale very well, the requirement was that client wanted to send back the logs of the streams back to 7digital via the API. This log data would be proportional to the number of users. 7digital had no facility for logging said data being sent from a client, so this would be a new problem to solve.
We needed to build an Web API which exposed an endpoint for a 7digital client to send large amounts of JSON formatted data, and to generate periodic reports based on such data. The expected volume of data was thought to be much higher than what the infrastructure in the London data centre was capable of supporting. It was very slow, costly and difficult to scale up the London data centre to meet the traffic requirements. It was deemed that building the API in AWS and transporting the data back to the data centre asynchronously would be the best approach.
Kafka was to be used to decouple the AWS hosted web service accepting incoming data from the London database storing it. Kafka was used as a message bus to transfer the data from an AWS region back to the London data centre. It was already operational with the 7digital platform at this time for non real time reporting purposes.
Since there was no need to use the London data centre, there was no advantage in writing another application in C# that could be hosted on the existing Windows webservers running IIS. Given the much faster boot times of Linux EC2 instances and the greater ease of using Docker in Linux, we elected to write the web application in Python. We could use Docker to speed up development.
The application used the Flask web framework. This was deployed in an AWS ECS cluster, along with a nGinx container to proxy requests to the python API container and an DataDog container which was used for monitoring the application
The API was very simple, once the inbound POST request was validated, the application would write the JSON to a topic on a kafka cluster. This topic was later consumed and written into a relational database so reports could be generated from it. The decoupling of the POST requests from the process that that writes to the database meant we could avoid locking the database, by consuming the data from the topic at a rate that was sustainable for the database.
Since reports were only generated once a day, covering the data received during the previous day, there could be a backlog of data on the kafka topic; there was no requirement for Near Real time Data.
In line with the usual techniques of software development at 7digital, we used tests to drive the design of this feature and were able to achieve continuous delivery. By creating the build pipeline early on, we could build the product in small increments and deploy them frequently.
We had the ability to run a makefile on a developer machine which built a docker container running the Python web app. We could then use the Python test frame unittest to run unit, integration and smoke tests for our application. Â The integration tests were testing if the app could write to Kafka topics and the smoke tests were end to end tests, which ran after a deploy to UAT or Production to verify a successful deployment.
We successfully completed the project and the web application worked very well with the inbound traffic from the client. Since it was hosted in an EC2 cluster we could scale up both the number and the resources of the instances running our application. The database was able to cope with the import of the voluminous user data too. It served as a good example of how to develop an scalable web API which communicated with a database located in a datacentre. It was 7digital’s first application capable of doing so and remains in use today.
Fixing 7digital’s Music Search, Part Three: The Virtuous Circle of Success
Posted by Michael Okarimia in 7digital, API, Automation, Lucene, search, SOLR on September 25, 2015
This is the third and final post in a series about how we improved the catalogue search at 7digital. You can start at Part one, or skip to Part two
We succeeded in improving 7digital’s music search results accuracy by using customer feedback, application monitoring and metrics, and continuous delivery.
A major factor in allowing us to complete the task was our Continuous Delivery pipeline, comprised of an automated Teamcity deployment process and a test environment which was effectively identical to our production environment.
From the git push of our tests and code, it took 15 minutes to deploy changes to Production. The work flow was automated in the test environment and then finally deployed to production with a human clicking the deploy to PROD button.
From the push, code was compiled, unit and integration tests were run, the application was deployed to test environment automatically and then acceptance tests were run on the test environment.
We would routinely then deploy the new code to only one server in the cluster as a “Canary release” a.k.a “canary deploy” and monitor that server for 10 minutes to ensure it had not adversely affected performance. If the change was for the worse we could immediately roll back the change and deploy the previous version of the code on the “canary server”.
Otherwise after monitoring performance, we would deploy the new code to the remaining production servers, and let our users enjoy the new improvement.
The rapid feedback allowed for multiple deploys to production to be made a day, with low risks of errors, since we practised Test Driven Development.
Beyond the response time, we wanted to analyse the accuracy of the search results themselves on production. To that end we used our Logging Platform built on the ELK stack (Elasticsearch, Logstash, Kibana) to see what the most common search results were, what number of queries were yielding 10 or fewer matching results, all in near real time.
We called this Kibana dashboard our Search quality dashboard.
We measured success by the reduction of query time and improved accuracy of results. As part of the acceptance tests we created acceptance tests which tested the search results for a list of given terms.
SOLR & Lucene search in a nutshell
Lucene is a full text search engine.
A document is sent to Lucene. Lucene will look at the document, analyse it’s fields, convert the text in the fields into terms (a process called tokenising) and store those terms with the document into an index.
An index can contain millions of documents.
This process adding documents to an index is called indexing.
Search terms can be sent to a index to query it. Lucene will return any documents that have terms matching the search term.
SOLR is a web service which wraps around a instance of Lucene. One can send documents to SOLR via HTTP and it will add those into a Lucene index. Queries can also be sent over HTTP to the Lucene index via SOLR and SOLR will return the search results via HTTP too. The index can be administered via HTTP requests sent to the SOLR web service.
Continuously Delivering Search Improvements
For our track & release indexes, creating a new index of the music catalogue on a regular basis meant we could take advantage of the index time features that SOLR offers.
Searches for track and releases used both SOLR and the internal Web API.
The catalogue Web API can accept up to 500 release or track IDs in a single GET request and return the metadata for all of them in a single response. The catalogue API would only fetch the content if the IDs were valid, but would also filter those results based on the complex licensing agreements 7digital have with both the music labels and 7digital’s clients.
This new smaller search index has meant:
- we could create a brand new index within an hour, meaning up to date data (previously, index creation took several days);
- have longer document cache and filter cache durations, which would only be purge at the next full index every 12 hours, this helped performance;
- it was quicker to reflect catalogue updates, as the track details were served from the SQL database which could be updated very rapidly.
Prior to the start of the redesign of 7digital’s catalogue search service, clients had complained that the accuracy of the search results for track and release searches was not useful.
After gathering feed back from users, both internal and external to 7digital, we came up with a list of specific search terms and the expected results, none of which the search algorithm was returned.
We sought to remedy this. This was achieved by modification of the Lucene’s term frequency weighting in the similarity algorithm.
It transpired that to meet our customers expectations we would have to delve into the inner workings of SOLR and Lucene to override the default search behaviour.
Search quality dashboard enabled us to view how search terms were received from clients and how a SOLR query was built and then sent to our SOLR servers.
Filtering out matching yet inconvenient results
Some labels deliberately publish tribute, sound-alike and karaoke tracks with very similar names to popular tracks, in the hope that some customers mistakenly purchase them. These tracks are then ingested into our platform, and 7digital’s contract with those labels means we are obliged to make them available. At the same time, consumers of our search services complain that the karaoke and sound-alike artists are returning in the search results above the genuine artists, mostly because of the repeated keywords in their track and release titles.
In order to satisfy both parties, we decided to override default Lucene implementation of search and exclude tracks, releases and artists that contained certain words in their titles, unless the user specifically entered them in as search term. For example, searching for “We are the champions†now returns the tracks by the band Queen, which is what customers expect. To achieve this we tweaked the search algorithm so all searches by default it will purposefully exclude tracks with the text “tribute to†anywhere in their textual description, be it the track title, track version name, release title, release version name or artist name.
The results look like this: https://www.7digital.com/search/track?q=we%20are%20the%20champions%20queen
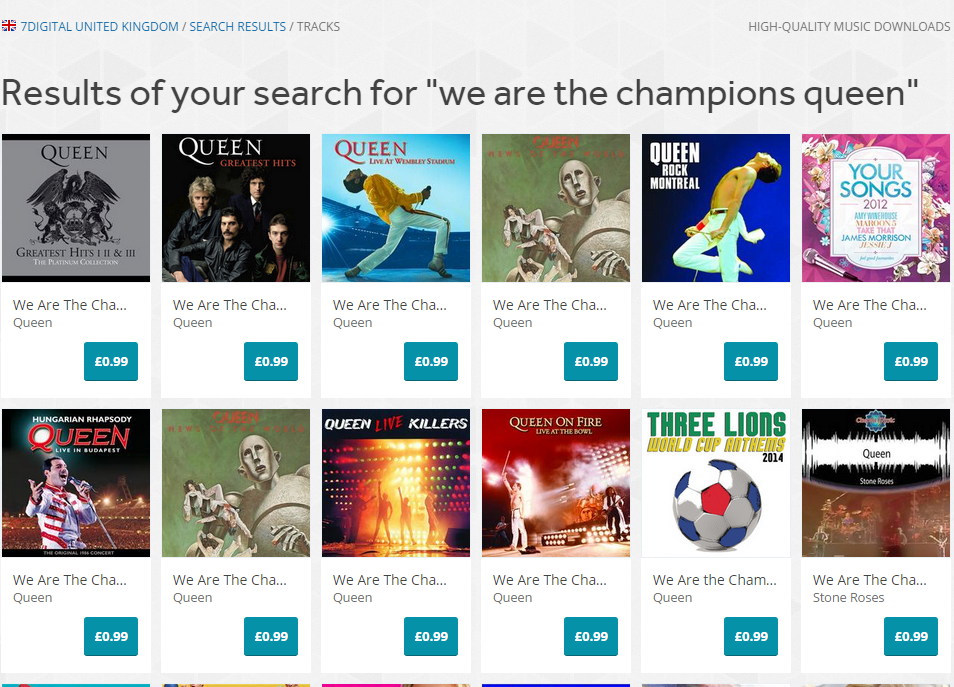
Filtering out tribute acts
Prior to the change, all tribute acts would appear in the search results above tracks by the band Queen. To allow tribute acts to still be found, the exclusion rule will not apply if you include the term “tribute to†in your search terms, as evidenced by the results here: https://www.7digital.com/search/track?q=we%20are%20the%20champions%20tribute%20to%20queen
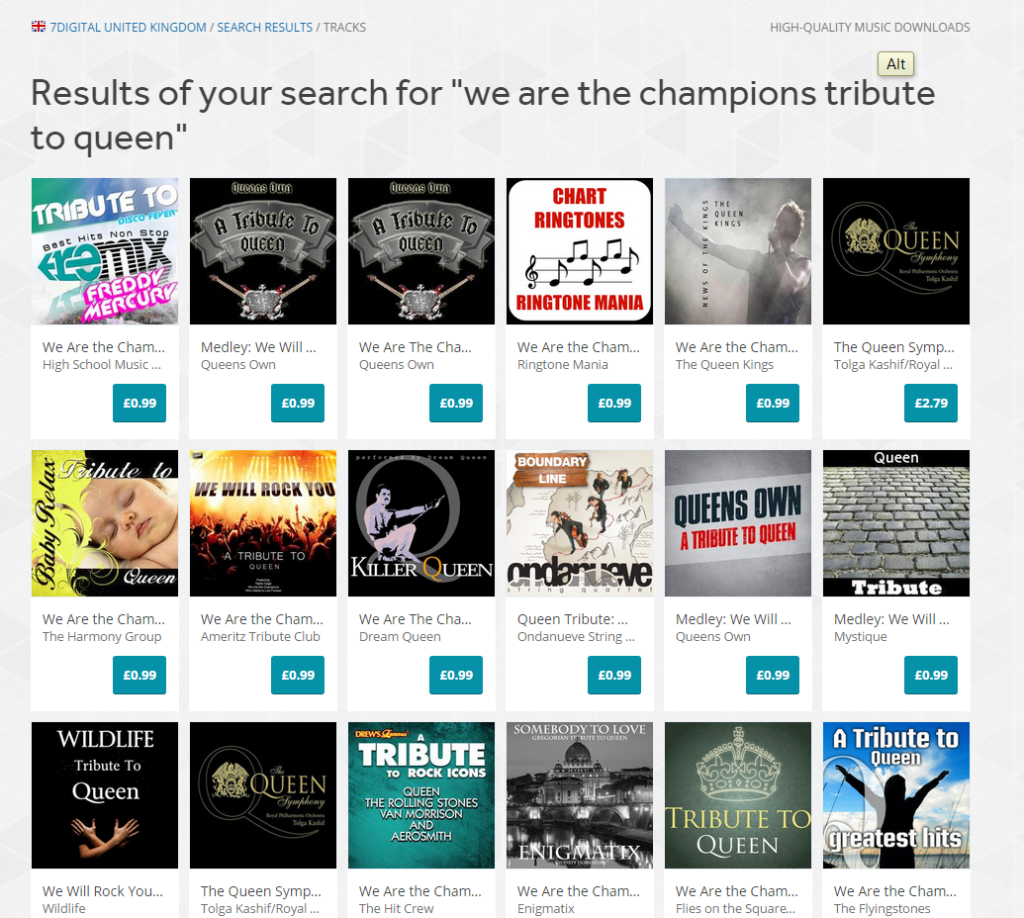
Tribute releases were incorrectly higher in search results
Other music labels send 7digital a sound-alike recording of a popular track, and name it so it’s release title and track tile duplicate the title of a well known track. By ranking results by popularity, the releases with deliberately misleading titles would rank lower in the search results as our customers tended identify the originals and play and purchase them more frequently that the sound-alike releases. This would mean those releases would be calculated to become more popular and at the next index rebuild time would find themselves higher in the search results, thus inducing a virtuous circle.
Tailoring Lucene for music search
Lucene is a capable search engine which specialises in fast full text searches, however the documents it is designed to search across work best when they are paragraph length containing natural prose, such as newspaper articles. The documents that 7digital add to Lucene are models of the metadata of a music track in our catalogue.
Standard implementation of Lucene will give documents containing the same repeated terms a higher scoring match than those that contain a single match. This is means when using the search term: “Michael†results such as “The Best of Michael Jackson†by “Michael Jacksonâ€, will score higher than “Thriller†by “Michael Jackson†because the term “Michael Jackson†is repeated in the first document, but not the second. We solved this issue by overriding the default similarity algorithm in Lucene for our installation of SOLR.
With regard to matching text values this makes sense, but for a music search we want to factor in popularity of our releases based on sales and streams of it’s tracks.
Ignoring popularity leads to a poor user experience; since “Best of Michael Jackson†release is ranked as the first result, despite being much less popular than “Thriller†which is ranked lower in the search results.
Indexed Terms and Stored Terms
The smaller index size meant that we could add fields to each document which weren’t displayed (called stored fields) but could be matched against a search term or influence the search results (called indexed fields). This meant index time features such as filter factories could be applied to certain indexed fields in a document to create terms which would be matched to the client’s search term https://wiki.apache.org/solr/AnalyzersTokenizersTokenFilters
These terms would not be returned in a search result, but were likely to match a user’s search term.
We also added functionality to support auto-complete style searches. Partial search terms could be sent to SOLR and by using Edge n grams filters at index time to create terms we achieved a simple prefix search.
For a document, a shingled and prefix field was added along with fields which were analysed by the standard filters. At query time we could alter the weighting of how important a field was to be when generating the SOLR query.
One useful tokeniser was the Text shingling filter which when applied to track titles such as “How Big, How Blue, How Beautiful” by Florence + The Machine.
The terms generated would include “How Big”, “How Blue”, “How Beautiful”. Search terms sent to Lucene including any of those tokens would match the track document
In addition to tweaking the search algorithm we also could make certain search terms synonymous with others. We created a Git repository on Github with public access; anyone can submit to us a pull request to add new synonyms for our search platform. We can choose to accept the search synonym to our platform and the change will be effected on our search API within 12 hours of our acceptance of change. Repository is here: https://github.com/7digital/synonym-list
Conclusion
Given that there are 40 million tracks in the 7digital catalogue, there is almost endless scope for tweaking the search results. Improving the search algorithms in Lucene to maximise customer happiness was an engaging experience, with the talented team at 7digital I found it to be a highly enjoyable time. We certainly left the music search in a better state than we found it.
And of course, we could upgrade it to Elasticsearch for even more features….
Fixing 7digital’s Music Search, Part Two: The 88% Speed Improvement
Posted by Michael Okarimia in 7digital, API, Automation, CFEngine, DevOps, search, SOLR, Vagrant, Virtualization on August 18, 2014
I’m Michael Okarimia, and I’m Team Lead Developer of the Content Discovery Team at 7digital, starting from Jan 2014. The Content Discovery team recently improved the catalogue & search infrastructure for the 7digital API. This post is the second in a series which explains how we turned resolved many of the long standing problems with 7digital’s music search and catalogue platform. If you haven’t read the first post in the series, which explains the problem of making 27 million tracks searchable, go and start reading from there.
In this post I detail how we improved the track search service so it’s response times reduced by 88%.
How we fixed track search: From 2014 onwards
As discussed in the previous post in this series, the data store used for searching tracks was a Lucene index being used as a document store, totalling 660gb in size. It was clearly far too large, and a scalable alternative had to be found. We also had to solve the inconsistency problems what arose due to the search index never being as up to data as the SQL database used to power the rest of the platform. These problems manifested themselves to API users as sporadic internal server errors when ever they wanted to stream or purchase a track that was returned from a search result.
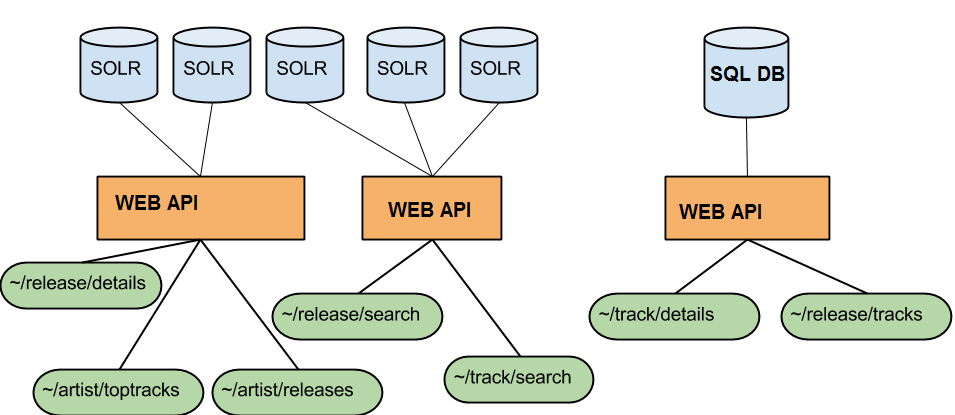
Search and Catalogue API endpoints with their different databases. This caused inconsistencies, but it increases availability
Rather than using Lucene as both a document store and a search index, we decided to create a new search index based on the searchable fields only, and use it to resolve 7digital track IDs. Armed with the track IDs that matched the search terms, we could do a look up on the catalogue database and then return that as the result. At the time we thought this should fix the inconsistency problem, and perhaps make searching faster.
Given that we were all relatively new to the team, we did some through investigation of the the search platform. We discovered that the previous schema in production was indexing fields like track price which were never actually searched upon. Additionally all of the twenty nine fields were stored, which was needed because it was used as document store. This increased the size of the index.
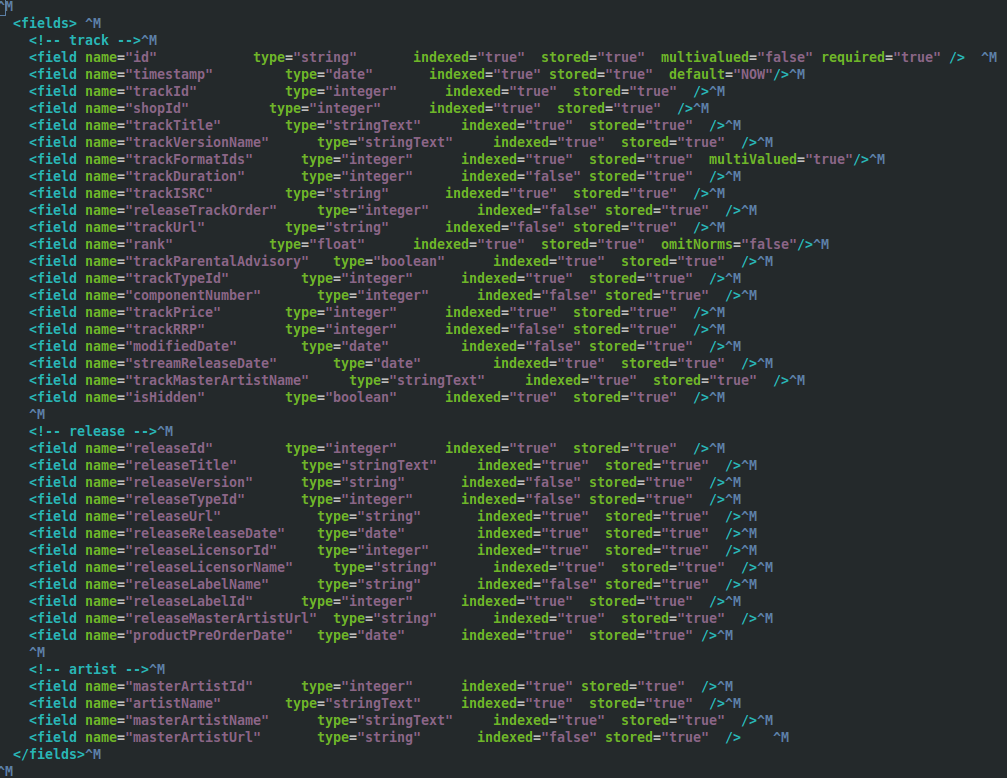
The index used to be set up as a document store, which made is slow to query
We created a prototype and came up with a much smaller search index, around 10 Gb in size compared with 660Gb. This new index contained only the searchable fields, such as track title, artist name and release title, reducing the schema down from twenty nine indexed fields to just nine.
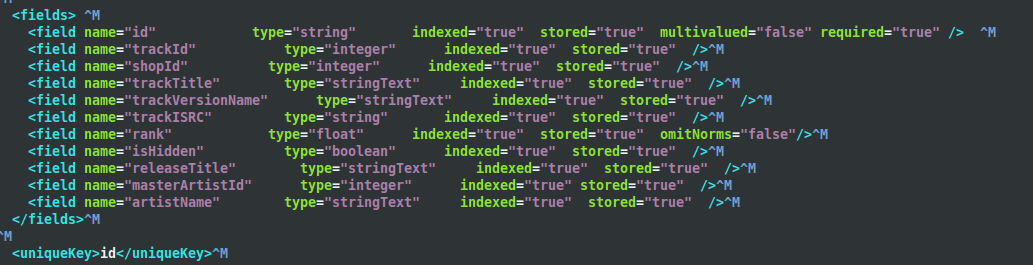
The new track schema, containing only searchable fields
When querying the new smaller index, the response would only contain the track IDs. However the response from the track search API endpoint is more than a list of track IDs. It is enriched with ample track metadata that can be used to build results in a search results page. There had to be a second step to fetch this data.
The returned IDs would then be used to look up the details of the track (such as it’s title, price and release date), and then the track details were composed into a single, ordered list of search results. The meant that the modified track/search endpoint would then return that list, which looked exactly like the old track/search responses that were returned from the giant index.
There was already an API endpoint that returned the contents of a track, namely, the ~/track/details endpoint. When given a 7digital track ID it returns all the available track meta data, such as track title, artist name, release date, etc. It’s response lacked some of the fields we require that were returned in the track search responses, so we added them so it now returns the price and available formats of a track.
We built this second index and deployed it to production in parallel with the gargantuan 660Gb one. One by one we rewrote the search & catalogue API endpoints so they instead used the smaller index to fetch matching track IDs and then called the ~/track/details endpoint to populate the results.
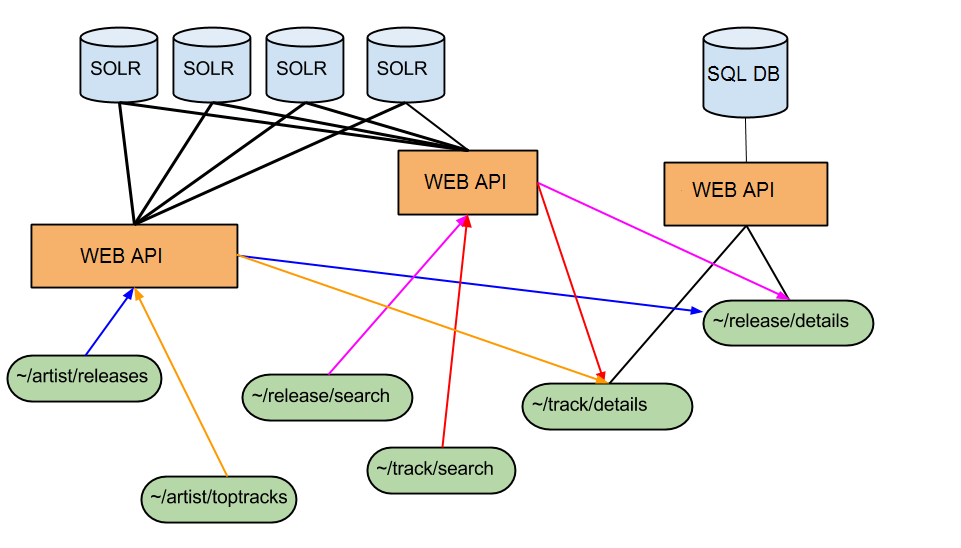
Catalogue and Search Endpoints as of July 2014. All responses are populated from the SQL DB which is most up to date. There are no longer inconsistencies
To test that the schema changes worked we learned that the best way was to use Vagrant and Test kitchen prior to pushing the schema to our continuous integration platform. We used CFEngine configuration management tool to define our SOLR schemas with the configuration file edited locally on a developer’s machine. Next we spun up a Vagrant instance that would apply the configuration defined in the file, and would then run Server Spec tests to verify some of the basic functionality of the SOLR server, using the altered schema. This arrangement was informed by our prior work to test infrastructure code, which I previously blogged about. Once the initial schema changes were known work on SOLR, we pushed the new schema up onto our continuous integration platform, something which Chris O’Dell has blogged about more eloquently than I could. Part our deployment pipeline then ran acceptance tests against the API endpoints which use this index, verifying that existing functionality was intact.
Using this technique, we migrated our APIs that relied upon this gargantuan 660Gb index to use the new smaller one instead. At the time of writing it is 100 times smaller, weighing in at 6.3 Gb.
The new smaller search index came with a number of advantages;
- being reliant on the ~/track/details endpoint meant we always returned current results, and we were 100% consistent with the rest of the API, which eliminated the catalogue inconsistencies problem;
- we could create a brand new index within an hour, meaning up to date data;
- much faster average response times for ~/track/search, reduced the response time by 88% from around 2600ms to around 350ms;
- no more deleted documents bloating the index, thus reducing the search space;
- longer document cache and filter cache durations, which would only be purge at the next full index every 12 hours, this helped performance;
- quicker to reflect catalogue updates, as the track details were served from the SQL database which could be updated very rapidly.
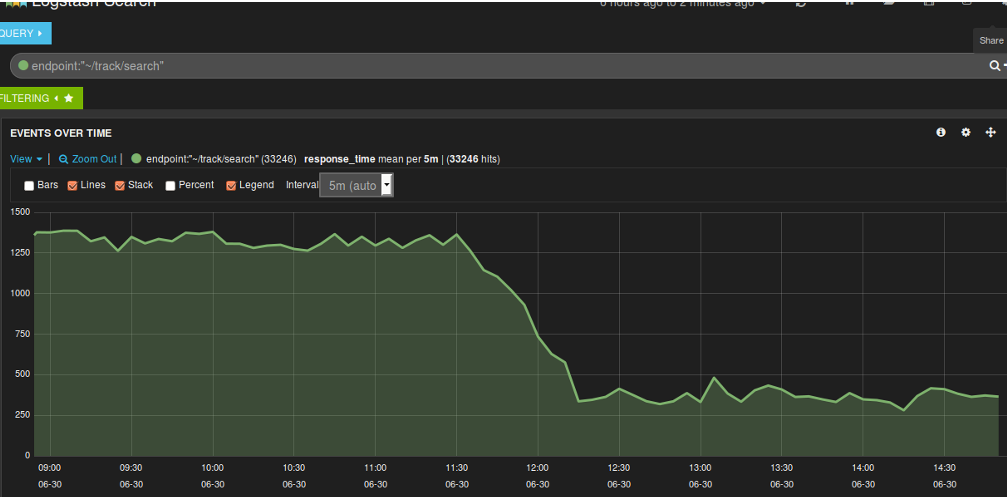
Y Axis units in milliseconds. Once we used a smaller index and enabled filter caching, the response time dropped.
Now that the entire index could fit in the memory of the server hosting it, this gave advantages such as:
- faster document retrieval;
- no more long JVM running garbage collection processes causing performance issues and server connection time outs. These were triggered replication when the index was changed, this now only occurred twice a day when the index was rebuilt;
- The platform could now cope with more traffic, based our our load tests using JMeter
Searching for Music Releases
We have also started this strategy for our release search endpoint. This endpoint performs searches for on the metadata of a music release based on the search terms. For example, one can search for either an artist or a release title. This endpoint queries a Lucene index containing data about music releases which is used as a massive document store as well as a search index. There are around 2.7 million releases in 7digital’s catalogue that are searchable.
We have integrated a call to the ~/release/details endpoint for each release ID returned in the results of a query to the ~/release/search index. This makes the endpoint always consistent with the catalogue DB, which fixed the inconsistency problem we had when searching for releases. At the time of writing we haven’t yet built a smaller release index which would improve response time, but this work is already under way.
We aim to reduce the size of the release index too and be able to build a new one multiple times a day.
For our track index, creating a new index of the music catalogue on a regular basis meant we could take advantage of the index time features that SOLR offers. I’ll write about how we used those features in a future post.
What we learnt
Never* Avoid, if possible incrementally add or delete documents to or from a Lucene index without rebuilding it regularly. Otherwise you will have an index filled with unsearchable but deleted documents which will bloat the index. This means you will inexorably experience search query times slowing over time;Never* Avoid using Lucene as a document database, it won’t scale to work effectively with millions of richly annotated documents;- Make sure your index can fit in the memory of the server it’s hosted on;
- Index as few Lucene fields as possible;
- Store as few Lucene fields as possible;
- Replication will invalidate your SOLR caches, and will trigger long running JVM garbage collections, try to minimise how often it happens;
- If you are using a Master/Slave SOLR configuration, slaves with differing replication polling intervals will lead to inconsistent responses when you eventually query the oldest non-replicated slave;
- Storing your index on Solid State Drives will speed up query time;
- Regularly rebuild your index to keep it small;
If you’re in interested in some more context of how we decided upon the implementation, my colleague Dan Watts has an excellent write up on his blog, detailing some of the problems that I mention in this post.
*Updated my opinion on how to Lucene upon reflection of Nick Tune’s comments.